
Category: eucalyptus - page 2
-
Importing Key Pairs in Eucalyptus
One of Eucalyptus’s oldest feature requests that people constantly ask about is the ability to import a pre-existing SSH key for use with instances. It even predates EC2’s support for doing that. I am happy to report that Eucalyptus 3.2 will at long last support it as well! (See the change on GitHub.) If you’re following Eucalyptus development, you can try this out right away with
euca-import-keypair. Chances are, your version of euca2ools already contains it.The thing that makes this feature really nice, however, looks like this:
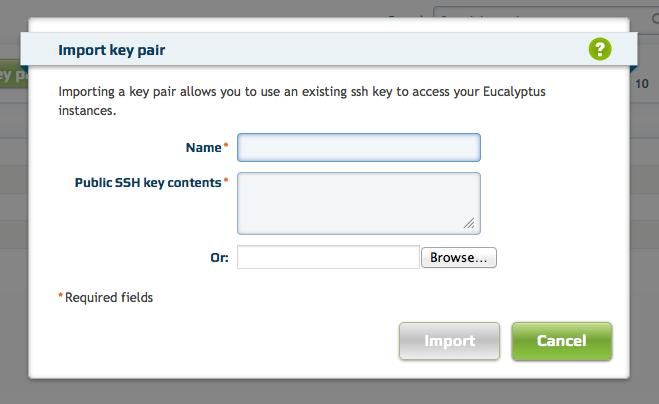
Just a few hours ago, the new web console that is slated to land alongside Eucalyptus 3.2 later this year gained support for importing key pairs as well. (See the change on GitHub.) I’m sure I am not alone in wanting to thank the contributors who added this.
-
Less Obvious Changes in Eucalyptus 3.1
Now that Eucalyptus 3.1 is out at last and we all get to wade through tons of announcements and blog posts, I thought I would mention a few of the changes that have happened since Eucalyptus 2 that you aren’t likely to see in marketing materials.
Why Eucalyptus 2? Most of us don’t get to use Eucalyptus 3.0, so comparing against that wouldn’t exactly be fair, would it? ;-)
Centralized documentation
The documentation for Eucalyptus 2 was strewn about the Eucalyptus website on a number of wiki pages. You had to read all of them to have any hope of ending up with a working cloud.
Eucalyptus 3’s documentation comes in the form of front-to-back PDFs. HTML documentation is forthcoming. You still need to read it all, but it is now in one place so you don’t have to go digging to find it.
The documentation’s source (in DITA format, if you find that sort of thing interesting) is also up on github, so there is now a way to fix errors: just send a pull request.
A new database
Eucalyptus 3.1 switches from HSQLDB to PostgreSQL. Given the number of Eucalyptus users I have seen over time who have experienced problems with HSQLDB’s behavior in the face of faults, I suspect this will make a lot of people happy.
Correct packaging
The RPM and DEB packages for Eucalyptus 2 fail to list a number of important things they depend upon, making the software needlessly complicated to install. In fact, this was so complicated that the popular FastStart distribution became the method of choice for getting started with a new Eucalyptus cloud.
This is no longer the case. Installation now consists of adding package repositories and telling one’s package manager to install a component. No more “install these dependencies first.” No more “download these packages separately and install them.” In fact, short of a script that writes Eucalyptus’s configuration for you, this completely obviates the need for FastStart.
RHEL 6 support
Eucalyptus 2 is supported only on CentOS 5. It also works on RHEL 5, but users of RHEL 6 and friends couldn’t even compile the stuff. That is now fixed; those operating systems now have full support.
A more usable configuration file
Eucalyptus 2’s configuration file jams everything into one huge list. Nothing gives any indication what Eucalyptus components actually care about each option. There is also no indication how options were affected by one’s choice of networking mode.
Eucalyptus 3’s configuration file and documentation break options down by component. For networking-related options, they also list the networking modes in which they apply.
Bugfixes
Eucalyptus 3 fixes bugs. Lots and lots of bugs. So many bugs that release notes cannot possibly list them all. In the future this will be easier, as every future bug report will now go through a new JIRA tracker.
What else?
Those are some of my favorites, but there are lots of other little improvements all over the place. Try Eucalyptus 3 out and see what you think. You may be pleasantly surprised.
-
Moving the Cloud Forward
It is sort of becoming a tradition for each member of the Fedora Board to declare a personal goal of some sort and then lead by doing. So now that I am the newest Board member, some people are curious about my plans.
In 2010 I helped get Fedora’s Cloud SIG off the ground. At that point in time our main goal was to get a modern version of Fedora running inside Amazon’s popular cloud, EC2. Nowadays the EC2 image is part of Fedora’s regular release process and the Cloud SIG has grown into one of Fedora’s most vibrant groups, added support for one self-hosted cloud platform, and is on the way to adding several more.
In light of that, the answer is obvious: I plan to help the Cloud SIG continue to be successful.
Of course, that’s a rather vague goal, so here are some examples of what success for the Cloud SIG has meant in the past:
- Building and testing EC2 images
- Adding the EC2-controlling euca2ools command line suite to Fedora
- Porting the cloud-init boot-time scripts to systemd
Now that those are done, here are some things success for the Cloud SIG may mean today:
- Add more cloud software, such as the relatively venerable Eucalyptus, to Fedora
- Continue to stabilize cloud-init on Fedora
- Help make PaaS software like OpenShift and Cloud Foundry work with IaaS software like Eucalyptus and OpenStack
Lofty? Possibly. But they are certainly all worth the effort!

Want to give one of these a shot? Are you interested in attending a hackfest or an activity day for moving the cloud forward? Leave a comment or stop by #fedora-cloud on Freenode!
-
Euca2ools: Past, Present, and Future
For those who don’t know, I work on the euca2ools suite of command line tools for interacting with Eucalyptus and Amazon Web Services clouds on Launchpad. As of late the project has stagnated somewhat, due in part to the sheer number of different tools it includes. Nearly every command one can send to a server that uses Amazon’s APIs should have at least one corresponding command line tool, making development of euca2ools’ code repetitive and error-prone.
Today this is going to end.
But before we get to that part, let’s chronicle how euca2ools got to where they are today.
The Past
Early euca2ools versions employed the popular boto Python library to do their heavy lifting. Each tool of this sort triggers a long chain of events:
- The tool translates data from the command line into its internal data structures.
- The tool translates its internal data into the form that boto expects and then hands it off to boto.
- Boto translates the data into the form that the server expects and then sends it to the server.
- When the server responds, boto translates its response into a packaged form that is useful for programming and returns it to the tool.
- The tool immediately tears that version back apart and translates it into a text-based form that can go back to the command line.
Things shouldn’t be this convoluted. Not in Python.
The Present
Tackling this problem involved coming up with ways to simplify not only the code, but also the process through which they are written. This led to two major changes, upon which all of the current euca2ools code is built.
“eucacommand”
The first step was consolidating all of the code involved in performing the first step of this process — reading data from the command line — into one location. Each tool then simply needed to describe what it expected to receive from the command line, and the shared code would take care of the rest. For example, let’s look at part of an older command, euca-create-volume:
class CreateVolume(EucaCommand): Description = 'Creates a volume in a specified availability zone.' Options = [Param(name='size', short_name='s', long_name='size', optional=True, ptype='integer', doc='size of the volume (in GiB).'), Param(name='snapshot', long_name='snapshot', optional=True, ptype='string', doc="""snapshot id to create the volume from. Either size or snapshot can be specified (not both)."""), Param(name='zone', short_name='z', long_name='zone', optional=False, ptype='string', doc='availability zone to create the volume in')]Because there are three
Params the shared code library reads three bits of info from the command line and hands them to the command’s code, which then hands them to boto, and so on.This methodology forms the basis for all of the current euca2ools that begin with “euca”.
Roboto
For a euca2ools command line tool to be useful it has to gather data from the command line, send these data to the server, and return data from the server to the user. A little-known boto sub-project written by boto developer (and former euca2ools developer) Mitch Garnaat, roboto, takes this statement literally and opts to let tools work at a lower level: instead of translating data from the command line into an intermediate format to send to boto, tools send these data directly to the server in the form that the server expects. The effect of this is that of essentially removing boto from the euca2ools code base altogether. By removing boto from the path that data have to take to get from the command line to the server and back, roboto makes tool writing and debugging simpler because there is less code to walk through and understand.
Roboto is the basis for all of the current euca2ools that begin with “euare”.
The Future
That is the state of the code today. Where do we go from here? While roboto allows one to create command line tools with a minimal amount of effort, it has several rough edges which prevented it from taking off and which make it sub-optimal for building out the hundreds of commands that the euca2ools suite will soon need to cover:
- User-unfriendly — When a user types something wrong or forgets to include something, roboto’s messages are often uselessly terse and unhelpful.
- A steeper learning curve than necessary — Roboto contains a large amount of custom code dedicated to fetching information from the command line. This steepens the learning curve for people who want to contribute code or fix bugs.
- Too much hardcoding — Roboto assumes that all tools do certain things, such as ascertaining what keys they should use to access the cloud, the same way.
- Still more work than it has to be — Though it makes writing tools simpler, roboto still hands each tool a bucket of information and expects the tool to pick out the bits the server needs and send them onward.
Enter requestbuilder
Requestbuilder is a new Python library that attempts to rethink the way roboto works in a way that is more familiar to the typical Python developer and requires less custom code to run. The easiest way to illustrate this is with an example.
A command line tool embodies a specific request to the server, so each such tool defines a Request that describes how it works:
class ListUsers(EuareRequest): Description = 'List the users who start with a specific path' Args = [Arg('-p', '--prefix', dest='PathPrefix', metavar='PREFIX', help='list only users whose paths begin with a prefix'), Arg('--max-items', type=int, dest='MaxItems', help='limit the number of results')] def main(self): return self.send() def print_result(self, result): for user in result['Users']: print user['Arn']Those familiar with Python’s argparse library will recognize the code inside
Arg(...), because requestbuilder does away with roboto’s custom code for reading things off the command line and instead lets argparse do the work. This cuts down on the amount of code we need to maintain, makes tool writing easier for developers who are already familiar with the Python standard library, and makes command line-related error messages much more user-friendly.When the tool starts running, requestbuilder uses data from the command line to fill in a dictionary called
argsand runs the tool’smainmethod, whose job is to process this information and fill in the portions of the request that will be sent to the server:params,headers, andpost_data, and then run thesendmethod to send it all to the server and retrieve a response. Attaching each of these sets of data to the request instead of passing them around between methods allows one to send a request, tweak it, and send the tweaked version as well.Why doesn’t the code above fill any of these things in? Since most of the data that comes off the command line goes directly to the server, when a tool runs
sendrequestbuilder will automatically fill inparamsfrom the contents ofargsso the tool doesn’t have to: whatever the user supplied with--prefixat the command line gets sent to the server with the namePathPrefix, and so forth.But what if something should not be sent to the server? While data from the command line go into
paramsto be sent to the server by default, one can tell requestbuilder to send a particular bit of data elsewhere instead:Arg('--debug', action='store_true', route_to=None)Noneinstructs requestbuilder to leave the “debug” flag alone and not attempt to send it anywhere. Data can also go elsewhere, such as to the connection that gets set up as the tool contacts the server:Arg('-I', '--access-key-id', dest='aws_access_key_id', route_to=CONNECTION)Astute readers will note that I haven’t described what
EuareRequestin the earlier example does, so here is the code for that:class EuareRequest(BaseRequest): ServiceClass = Euare Args = [Arg('--delegate', dest='DelegateAccount', metavar='ACCOUNT', help='''[Eucalyptus extension] run this command as another account (only usable by cloud administrators)''')]Requestbuilder makes tool writers’ jobs easier by allowing one type of request to inherit its command line options from another type of request and then supply their own by simply listing more of them. This is a little different from the way Python usually works; Requestbuilder does some magic behind the scenes to make this possible. As a result, everything common to commands that access the EUARE service (Eucalyptus’s equivalent of Amazon’s IAM service) can go into one place to be shared with others.
The final piece of information requestbuilder needs is a
ServiceClass, which describes the web service that the tool connects to. A service class is another simple bit of code that looks like this:class Euare(BaseService): Description = 'Eucalyptus User, Authorization and Reporting Environment' APIVersion = '2010-05-08' EnvURL = 'EUARE_URL'The net gain from all this is a smaller, but much more flexible code base that should be able to scale better than anything we have had before. Requestbuilder’s use of Python’s argparse library also makes tools much more informative to users than ever before.
How You Can Help
We’re developing requestbuilder on GitHub as a project under the boto organization. We’re going to start rewriting euca2ools, one by one, improving requestbuilder to support new things as we go. It’s still early on, so if you have ideas to share or you’re interested in helping develop this code, now is your chance!
We’re also moving development of euca2ools itself to GitHub. This will make it easier to work on euca2ools and requestbuilder in parallel. It will also make it easier to share code with the rest of the boto community.
If you’re interested in getting involved, join us on the #boto or #eucalyptus IRC channels on Freenode. You can also send e-mail to Eucalyptus’s community list.