/dev/zero - page 5
The infinite stream
-
Speed Up Merges with Git's Index
We’ve all been there, running
git mergeonly to have it spewCONFLICTall over the place and quit partway through. But if we already know that every time there is a conflict then all of “our” code that we are merging changes into should take precedence over “their” changes that we are pulling in, git 1.7.3 provides a handy shortcut for that:$ git merge -X ours theirbranchIf “their” changes that we are pulling in should always take precedence instead then things are equally easy:
$ git merge -X theirs theirbranchIf “ours” or “theirs” style merges will work, but only for certain files, things get a bit more complicated. But with a bit of background knowledge of how git’s index works we can save ourselves a bunch of work.
The index stores what stage a file is in. Normally, a file’s stage is 0.
$ git ls-files -s myfile 100644 4b48deed3a433909bfd6b6ab3d4b91348b6af464 0 myfileA file with a merge conflict is different because the index actually has three different versions of it: the version that the two branches we are merging most recently had in common, the version on “our” side of the merge, and the version on “their” side of the merge. In git these correspond to stages 1, 2, and 3. This is one reason one has to run
git addon every conflicting file before completing a merge.$ git ls-files -s myfile 100644 4b48deed3a433909bfd6b6ab3d4b91348b6af464 1 myfile 100644 5be4a414b32cf4204f889469942986d3d783da84 2 myfile 100644 39c5733494077ae8bc45c45c15a708ffe9871966 3 myfileRather than opening up the conflicting file and clearing out the parts that clash by hand, we can instead simply copy the version we want from the index into our working tree:
$ git checkout-index -f --stage 3 myfile $ git add myfile $ git commit
-
Git Pull via Sneakernet
Today I found myself needing to move some commits between two repositories. In general the best way to do this is by pulling changes from one into the other, but in this case the repositories did not have direct access to each other. Rather than copying an entire repository from one machine to another or mucking about with a pile of patches, we can save time by performing the sending and receiving sides of the network-enabled
git fetchcommand by hand.In the source repository, add the changes we want to move to a bundle that we can copy to a USB stick:
$ git bundle create changes.bundle master..mybranch Counting objects: 5, done. Delta compression using up to 4 threads. Compressing objects: 100% (3/3), done. Writing objects: 100% (3/3), 313 bytes, done. Total 3 (delta 2), reused 0 (delta 0) $ cp changes.bundle /media/usbstickIn the destination repository, ensure that we have the commits necessary to use the bundle and then tell
git fetchto grab the changes from it:$ git bundle verify /media/usbstick/changes.bundle The bundle contains 1 ref 7a1d2087f10e6db33e6b4a28e2c427b65238a62c refs/heads/mybranch The bundle requires these 1 ref 6f5fced94ef76f1b46e259db72ad6fc39c49ba72 /media/usbstick/changes.bundle is okay $ git fetch /media/usbstick/changes.bundle mybranch Receiving objects: 100% (3/3), done. Resolving deltas: 100% (2/2), completed with 2 local objects. From /media/usbstick/changes.bundle * branch mybranch -> FETCH_HEAD $ git merge FETCH_HEAD Updating 6f5fced..7a1d208 Fast-forward README | 2 ++ 1 file changed, 2 insertions(+)
-
Useful Yum Commands: Installing by Path
Every once in a while I find myself trying to install something, but not knowing what package contains it.
# yum install g++ Setting up Install Process No package g++ available. Error: Nothing to doBut if you’re using a modern version of yum (i.e. that of RHEL 6 or Fedora) then you can simply tell it to install the program you’re looking for.
# yum install /usr/bin/g++ Setting up Install Process Resolving Dependencies --> Running transaction check ---> Package gcc-c++.x86_64 0:4.4.6-3.el6 will be installed --> Finished Dependency Resolution Dependencies Resolved
-
Moving the Cloud Forward
It is sort of becoming a tradition for each member of the Fedora Board to declare a personal goal of some sort and then lead by doing. So now that I am the newest Board member, some people are curious about my plans.
In 2010 I helped get Fedora’s Cloud SIG off the ground. At that point in time our main goal was to get a modern version of Fedora running inside Amazon’s popular cloud, EC2. Nowadays the EC2 image is part of Fedora’s regular release process and the Cloud SIG has grown into one of Fedora’s most vibrant groups, added support for one self-hosted cloud platform, and is on the way to adding several more.
In light of that, the answer is obvious: I plan to help the Cloud SIG continue to be successful.
Of course, that’s a rather vague goal, so here are some examples of what success for the Cloud SIG has meant in the past:
- Building and testing EC2 images
- Adding the EC2-controlling euca2ools command line suite to Fedora
- Porting the cloud-init boot-time scripts to systemd
Now that those are done, here are some things success for the Cloud SIG may mean today:
- Add more cloud software, such as the relatively venerable Eucalyptus, to Fedora
- Continue to stabilize cloud-init on Fedora
- Help make PaaS software like OpenShift and Cloud Foundry work with IaaS software like Eucalyptus and OpenStack
Lofty? Possibly. But they are certainly all worth the effort!

Want to give one of these a shot? Are you interested in attending a hackfest or an activity day for moving the cloud forward? Leave a comment or stop by #fedora-cloud on Freenode!
-
Fixing a Git Branch that Started in the Wrong Place
Today I did some work on a branch in git only to discover that I based it on some unstable code rather than the stable code that I usually want to use as a baseline.
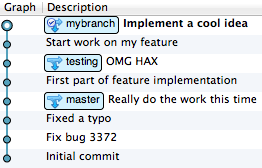
You can fix this by using a bit of git’s rebase magic:
$ git rebase --onto master testingThis moves the entire current branch onto another.